Phonesse¶
What is Phonesse?¶
Phonesse is a toolkit to extract, visualize, and search verbal sounds patterns from text. These patterns exists in normal language such as conversation or prose, but are often more obvious in media like poetry, song lyrics, and rap. What data will you phonesse?
What is it for?¶
- Extracting sound segments from text
- Documenting sound usage across genres, individuals, cultures, and tasks
- Visualizing verbal sound patterns
- Investigating sequences of sound segments (and poetic devices)
- Creating phonologically similar word sets (for experimental stimuli or for fun)
- Motivating linguistic and cognitive hypotheses
- Analyzing verbal sound patterns
Who is it for?¶
Anyone interested in sound patterns in language, especially those doing Data Science, NLP, or Corpus Phonology. Educators and literary analysts may also find the visualization tools helpful for examining language structure.
- Corpus Phonologists
- Literary Analysts
- Creatives
- Developers
- Data Scientists
Install & Load¶
Phonesse is a python pip package, you can download it with the pip command:
pip install phonesse
Inside of a python environment you can import the package as follow:
from phonesse import phonesse
Sound Segments¶
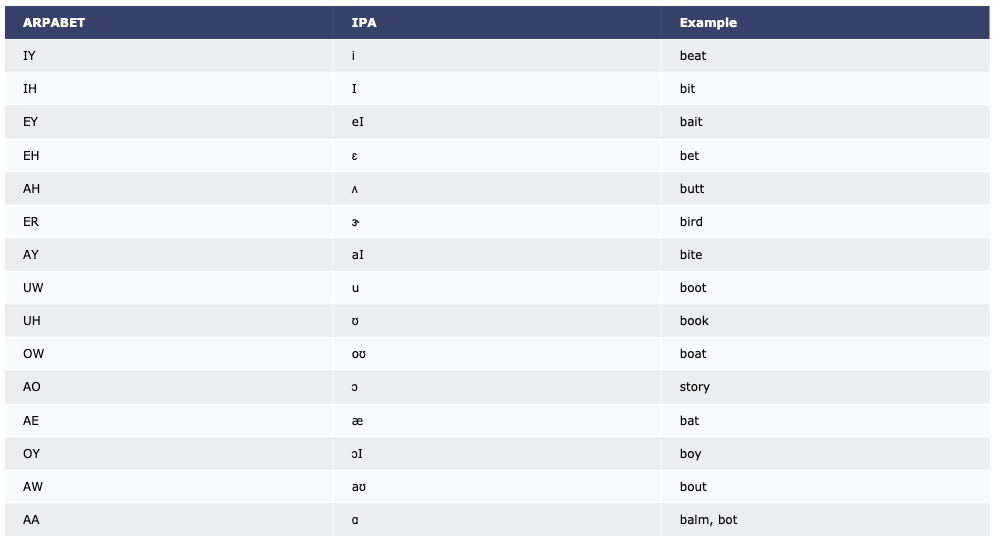
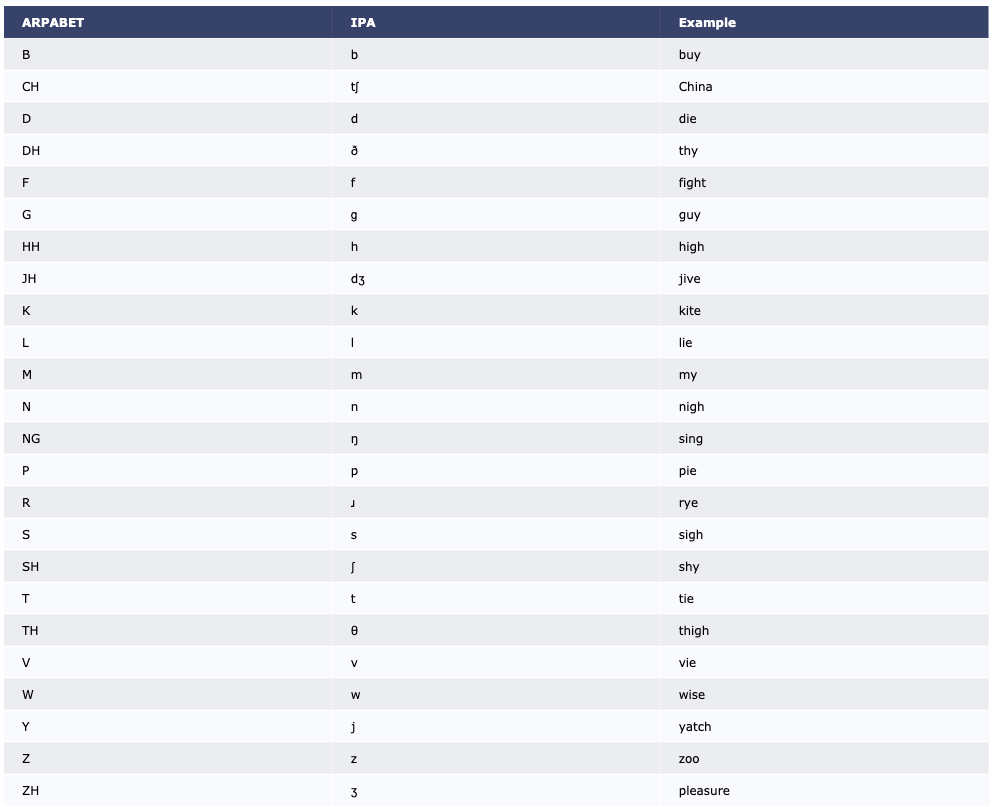
Phonesse uses the IPA to represent language sounds, specifically, a computer friendly version called ARPABET.
This info function show a table of IPA and ARPABET symbols, along with example words for each:
>>> phonesse.show_APRABET_examples() # should be called info
Natural Classes¶
Consonants and vowels group together in various ways. One of the higher order ways of grouping these segments is by their natural class. Often, researchers will use natural classes to refer to segments with some underlying similarity.
Identify Natural Class by Segment¶
It is easy to find the natural classes associated with any phoneme:
>>> phonesse.ARPABET_2_naturalclasses('IY')
['high', 'front', 'unrounded', 'sonorant']
>>>
>>> phonesse.ARPABET_2_naturalclasses('M')
['voiced', 'bilabial', 'nasal', 'sonorant']
Identify Segments by Natural Class¶
We can also find phonemes based on natural classes, or even natural class combinations:
>>> phonesse.naturalclass_2_ARPABET(['voiceless'], segments='all',logic='or')
[['CH', 'F', 'HH', 'K', 'P', 'S', 'SH', 'T', 'TH']]
>>>
>>> phonesse.naturalclass_2_ARPABET(['stop','voiceless'], segments='all',logic='or')
[['B', 'D', 'G', 'K', 'P', 'T'],
['CH', 'F', 'HH', 'K', 'P', 'S', 'SH', 'T', 'TH']]
>>>
>>> phonesse.naturalclass_2_ARPABET(['stop','voiceless'], segments='all',logic='and')
['K', 'P', 'T']
Sample Data¶
Often, the data we want to handle is from text sources or corpora.
Phonesse provides a simple ‘data’ class with a few smaller textual samples of different types.
List all the samples like so:
>>> phonesse.data.get_sample() # if no argument is given, all sample names are displayed
Pass one of the sample text names to data e.g. data('sonnet')
Sample Text names:
dict_keys(['sonnet', 'rap_eminem', 'limerick_1', 'limerick_2', 'inagural2009', 'battle_rap', 'random_sentences', 'wiki_sentences', 'rap_biggy', 'rap_mfdoom', 'bar_pong_rhymes'])
Select a textual sample like so:
>>> limerick_text = phonesse.data.get_sample('limerick_1')
>>> limerick_text
'A fly and a flea in the flue\n\tWere imprisoned, so what could they do?\n\tSaid the fly, "Let us flee!"\n\t"Let us fly!" said the flea.\n\tSo they flew through a flaw in the flue.'
Extracting Segments¶
There are plenty of tools to deal with lexical items (words), parts of speech, etc. Phonesse makes it easy to use the vast array of available orthographic corpora to perform larger scale studies on language sounds.
The ‘get_segments’ function takes a string of text, and returns a list of sound segments. By changing the ‘segments’ parameter, you can easily return different subsets of segments
- vowels
- stress
- vowels_stress
- consonants
- consonant_clusters
- syllables
- words
- word_initial
Let’s get all the vowels (in order) from the following text:
>>> phonesse.get_segments("It is this easy to get vowel segments from text", segments='vowels')
['IH', 'IH', 'IH', 'IY', 'IY', 'UW', 'EH', 'AW', 'EH', 'AH', 'AH', 'EH']
Changing the ‘segments’ parameter will make get_segments return different types of segment sequences:
>>> phonesse.get_segments("Just as easy to get the underlying stress pattern", segments='stress')
[1, 1, 1, 0, 1, 1, 0, 2, 0, 1, 0, 1, 1, 0]
>>> phonesse.get_segments("Or the first sound of each word", segments='word_initial')
['AO1', 'DH', 'F', 'S', 'AH1', 'IY1', 'W']
And we can use this function on larger sample texts too:
>>> phonesse.get_segments(phonesse.data.get_sample('limerick_1'))
['AH', 'AY', 'AH', 'AH', 'IY', 'IH', 'AH', 'UW', 'ER', 'IH', 'IH', 'AH', 'OW', 'AH', 'UH', 'EY', 'OW', 'EY', 'AH', 'AY', 'EH', 'AH', 'IY', 'AH', 'AH', 'AY', 'EH', 'AH', 'IY', 'OW', 'EY', 'UW', 'UW', 'AH', 'AO', 'IH', 'AH', 'UW']
Neural Network Safety Net¶
If things aren’t spelled correctly, or there are uncommon words, it’s O.K.! In the background, Phonesse uses a neural network to predict pronunciations for unknown words:
>>> phonesse.get_segments("Badd Sppellling is fine", segments='consonants')
['B', 'D', 'S', 'P', 'L', 'NG', 'Z', 'F', 'N']
N-grams¶
There are interesting things to discover when only looking at individual segments, but it is often useful to deal with sequences of segments. Of course, there are plenty of tools that specialize in n-grams (e.g. in ntlk), but here is a simple implementation that is good for most use cases.
The n_grams function takes a list of items and an n-gram order, and returns all n-grams up to n-gram order size. Specifically, it return a list of Counter dictionaries (can be handled like regular dictionaries), one dictionary for each sequence size.
Here it is in action:
phonesse.n_grams(['IH', 'IH', 'IH', 'IY', 'IY', 'UW', 'EH', 'AW', 'EH', 'AH', 'AH', 'EH'],2)

Visualize Language Sounds¶
Encoding relevant data is the first step, but it is also useful to sanity check and visualize what we have just encoded. Dan Levitin has suggested that “music can be thought of as a type of perceptual illusion in which our brain imposes structure and order on a sequence of sounds” (Levitin 2006). Verbal sound patterning may leverage a similar type of perceptual illusion, but built on top of, and often, smuggled into, language.
Sometimes we can even see this larger sound structure in musical notation or in other popular visualization tools like MIDI. On the other hand, it can be hard to notice verbal sound patterns when phonology is an aspect of language that we have all learned to take for granted (we always hear, but rarely pay close attention to language sounds). It is made even more difficult given that we only hear one sound at a time and never get to see the big picture, unlike in the visual arts, or in notational representations of music.
Our brains help us attend to some of this structure, but not all of it. Just as in music, visualizing language sounds in perceptually intuitive spatial configurations (and even colors) can help our brains impose more structure and order on them. As it turns out, these same representations (e.g. lists, grids, matrices) that are useful for visualizing sounds and sequences, are also amenable to computational and linguistic analysis.
Vowels & Colors¶
Sound can be represented in multiple ways. For a visually intuitive encoding we can use an insight from a paper on the relationship between colors and sounds. In 2017, Cuskley et al. show that high and front vowels are perceived as lighter, yellower, and greener than low and back vowels. We can use this finding to orient a color scale along a 2-dimensional vowel chart. The benefit is that we can create a perceptually valid vowel2color map, where more similar vowels are indicated by more similar colors. This is a very crude approximation. My colleagues and I are currently validating this mapping with a behavioral experiment. More coming soon.
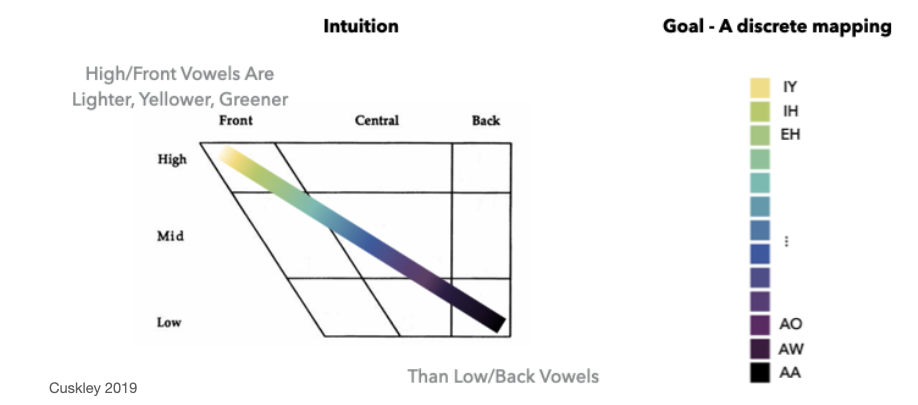
Phonesse has an info function that plots the current vowel2color map:
>>> phonesse.show_vowel_colors()

We can use this color-coding in various visual representations, such as the MIDI and Grid representations below.
For practical reasons, I focus on vowels visualization here. More on consonants in the future. Vowel sounds can be more easily analogized to musical sound (notes) for many reasons. One, there are a similar number of vowels in English and notes (pitches) in the western musical tradition (~15). Two, vowels are the most sonorant sounds and can exhibit rhythmic (stress) patterns much like those in music. Three, vowels are shown to be correlated with melody in musical lyrics, whereas consonants are not (Jonah Katz 2015).
MIDI¶
One way to visualize speech sounds is in MIDI format, a common format in music. This is much like singing, but using phonemes (vowels) from word words, rather than pitch, to create patterns.
Pass the ‘plot_as_MIDI’ function either a string of text or a phonomial (more on those below).
In a Jupyter Notebook. you can hover over the colored vowel blocks to see the words they are connected to:
>>> phonesse.plot_as_MIDI("It is this easy to see sound segments from text")
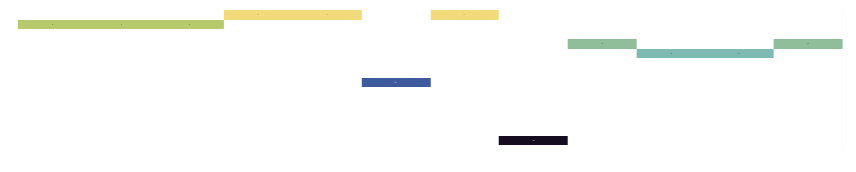
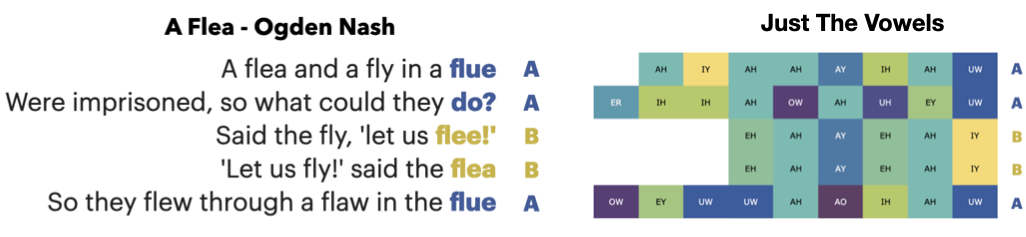
Here are the vowels from the “A Flea” Limerick, plotted in MIDI form:
>>> phonesse.plot_as_MIDI(phonesse.data.get_sample('limerick_1'))

Here are the vowels from Eminem’s “Lose Yourself” in MIDI form:
>>> phonesse.plot_as_MIDI(phonesse.data.get_sample('rap_eminem'))
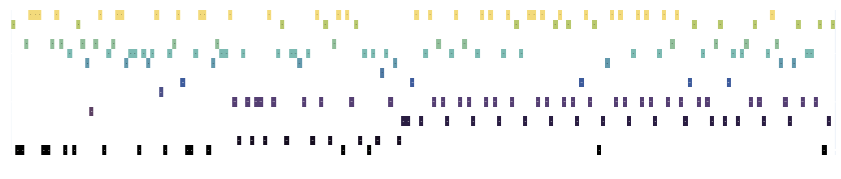
Eminem’s Lose Yourself shows enormous amounts of periodicity and structure that are so regular, they could easily be mistaken for beat or melody. Not only that, the patterns change, and even relations between patterns seem to have structure. This kind of complexity underlies a great deal of rhyming verse, however, we often do not notice it in such a holistic way.
Grids¶
Even encoded in color, some patterns can be quite difficult to see or interpret. Another way to visualize the sounds of language is to assume a bit more structure and display our color-coded sounds in a grid. Text, IPA, and MIDI representations are by default 1-dimensional. A grid, on the other hand, represents 2 spatial dimensions, a horizontal one, and a vertical one. Each row in the grid may represent their own meaningful utterance (e.g. sentences, lines, rhymes, words). These rows can then be right or left-aligned, according to the data in question.
Let’s look at an example. Take a moment to identify the largest poetic sound structures in this poem.

You likely noticed two patterns, repeated use of the /f/ + /l/ sound for alliteration, and an AABBA end-rhyme pattern, but did you find a third? The vowels of line 3 and line 4 are identical, a form of assonance. How do we so easily miss large patterns like this? The point is, we don’t always notice repeated sounds in language, even if the pattern is large and is in a context that we are actively examining.
Here is a right-aligned vowel plot of the same poem. We right-align it here because we know there is end-rhyming structure we may be able to observe.
Larger samples can also be plotted in this way, which can make their multi-syllablic structure much clearer to see.
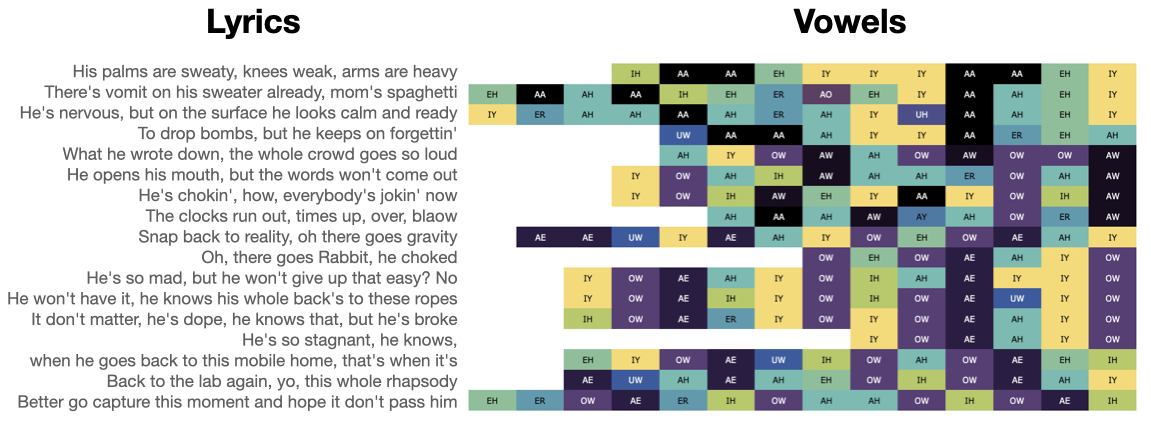
In a Jupyter Notebook. you can hover over the colored vowel blocks to see the words they are connected to.
Phonesse has an info function that plots colored vowels in grids:
>>> phonesse.plot_as_grid(phonesse.data.get_sample('limerick_1'))
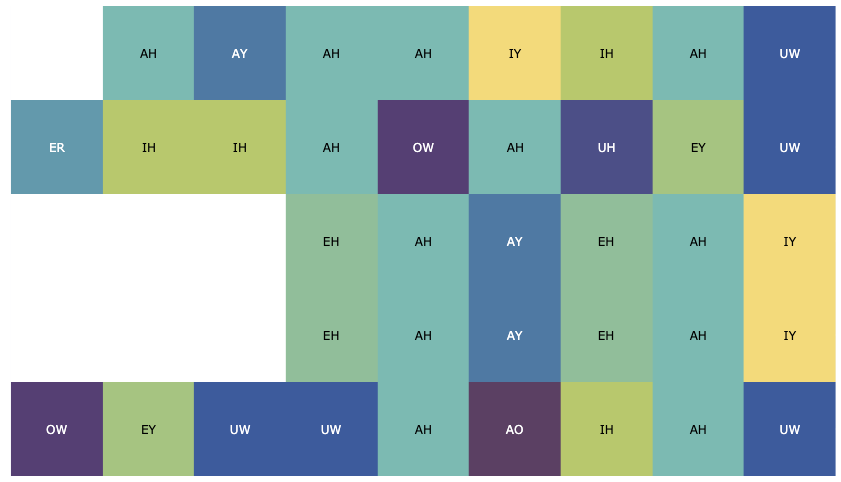
Here are the vowels from the “A Flea” Limerick, plotted in MIDI form:
>>> phonesse.plot_as_grid(phonesse.data.get_sample('rap_eminem'))
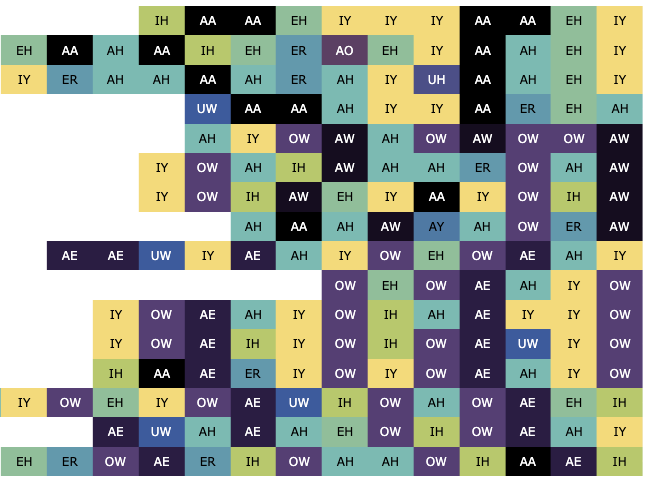
Notice above how much easier it is to orient ourselves to large-scale vowel patterns when viewing Eminem’s Lose Yourself verse in this way compared to MIDI (or orthography for that matter).
Phonomials¶
Under the hood, Phonesse uses a class called phonomials to encode and manipulate sound data. You may not need to bother with it, but sometimes it’s easier to directly use phonomials for processing.
A phonomial is just a python object, with a few attributes, that makes multi-term sounds pattern analysis more accessible.
Here we encode a string of text into a phonomial object:
>>> my_phonomial = phonesse.phonomial.from_string("blacksmith")
>>> my_phonomial
We can get the orthography used to encode the phonomial:
>>> my_phonomial.ortho
'blacksmith'
Sequences of language sounds in words can be encoded numerous ways, the most standard being syllables and CVC. Phonomials has full support for CVC blocks, full syllable support coming soon.
Alternating CVCVC patterns here encode each C as a consonant cluster, and each V as a vowel sound.
A visualization of these forms and how they are represented in phonomials is below.
CVC blocks look like this:
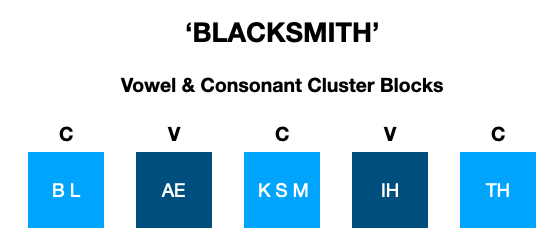
We can get the CVC block structure from a phonomial like so:
>>> my_phonomial.blocks
[['B', 'L'], ['AE', 1], ['K', 'S', 'M'], ['IH', 2], ['TH', '.']]
Syllables look like this:
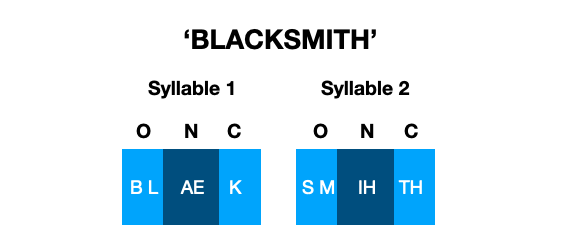
O = onset; N = nucleus; C = coda - these are all components of a syllable, which are structured as shown above.
We can get the syllabic structure from a phonomial like so:
>>> my_phonomial.syllables
[[['B', 'L'], ['AE', 1], ['K']], [['S', 'M'], ['IH', 2], ['TH', '.']]]
Notice that the main difference between these representations in the example ‘BLACKSMITH’ is that the K S M consonant cluster is split in the syllabic representation; K being in the coda of the first syllable, and S M being in the onset of the second syllable.
Often the questions we can ask about language sounds are not impacted by this kind of distinction. That said, syllables are linguistically and psychologically important units, full support for syllables coming soon (currently missing a neural network to provide pronunciations for missing or misspelled words).
We can also just dump out the full contents of a phonomial:
>>> my_phonomial.__dict__
{'blocks': [['S'],
['AW', 1],
['N', 'D', 'Z', '.', 'G'],
['UH', 1],
['D', '.']],
'syllables': [[['S'], ['AW', 1], ['N', 'D', 'Z', '.']],
[['G'], ['UH', 1], ['D', '.']]],
'cmu_word_prons': [['S AW1 N D Z', 'S AW1 N Z'], ['G UH1 D', 'G IH0 D']],
'cmuS_word_prons': [['S AW1 N D Z', 'S AW1 N Z'], ['G UH1 D']],
'ortho': 'Sounds good'}
The cmuS_word_prons represents a syllabic encoding of the text by word, cmu_word_prons is an unsyllabified encoding. The period (.) annotates the separation between words.
NOTE: All plotting functions that take text (e.g. plot_as_MIDI, plot_as_grig) also accept phonomial objects.
Word Sets¶
Generating Word Sets¶
Most rhyme search tools require you to search based on a single word. But sometimes we might want to start with a sound pattern, and find all matching words. Phonesse provides a sound-search widget that lets you build a sound pattern and get all the words that contain the pattern.
The phonesse.search_widget takes a single argument, ‘syllables’. You can create sound patterns of different length by changing the number you pass to ‘syllables’. Running the widget function will generate a search interface. Select sound segments to match in each consonant and vowel position, and choose an alignment (i.e. where should the pattern occur in matched words).
This simple tool can be used to find rhymes or words with other phonological similarity. The resulting sets of words can also be used in behavioral or corpus studies of language, or for creative purposes… (More features and a web app coming soon.)
Run the widget to build a 2 syllable pattern:
>>> phonesse.search_widget(syllables=2)

Run the widget to build a 3 syllable pattern:
>>> phonesse.search_widget(syllables=3)

Visualizing Word Sets¶
A quick processing of the results allows us to plot and visualize their underlying sounds:
>>> matches = 'absorb absorbed absorbs cobweb cobwebs ebarb flashbulb habeeb habib hobnob hubbub imbibe imbibed lightbulb lightbulbs nabob nabobs oversubscribe oversubscribed reabsorb reabsorbed rhubarb subscribe subscribed subscribes suburb suburbs suburbs undersubscribed unsubscribe unsubscribed'.split(' ')
>>> matches = '\n'.join(matches)
>>>
>>> phonesse.plot_as_grid(matches)
Plot stress:
>>> phonesse.plot_as_grid(matches,mode='stress')

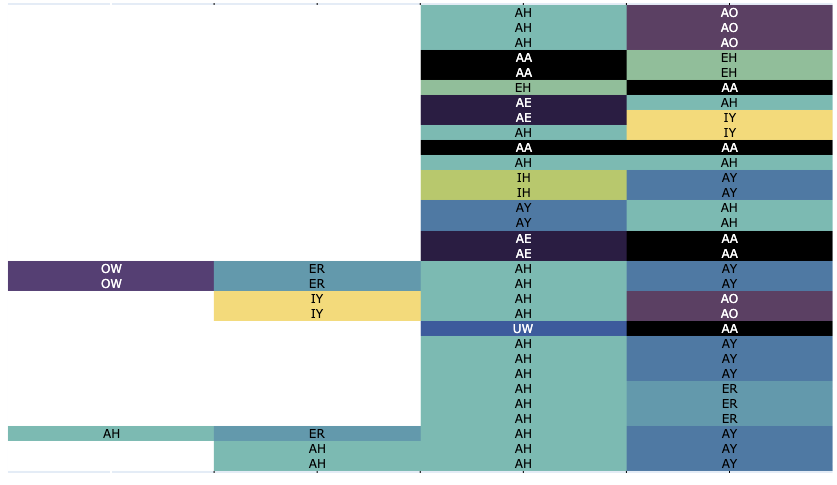
We can do the same thing with any set of words, here are the vowels of the words that match the * ER * ER * ER * patterns (* means match everything):
>>> matches = 'afterburner afterburners ernsberger ferderer herberger hershberger herzberger kirchberger murderer murderers murderers nurnberger nurturer paperworker paperworkers perjurer schermerhorn sternberger verderber'.split(' ')
>>> matches = '\n'.join(matches)
>>>
>>> phonesse.plot_as_grid(matches)

Plot stress:
>>> phonesse.plot_as_grid(matches,mode='stress')
Analyzing Word Sets¶
The plots above make visible some of the structure in the vowels and stress of these phrases, but there is also variation in these columns. One thing we can do to describe the underlying sound variability in sets of phrases is to quantify how predictable each consonant or vowel position (column) is.
In one of our past examples, we searched for a 3 syllable pattern where all vowel sounds were “ER”. So we held vowel positions constant, but how much variation exists in the underlying stress of those vowels, or in the consonants that surround them?
We can use Shannon entropy to determine how predictable each position is in terms of the frequency of sounds that appear there. Lower entropy means more predictable, higher entropy means less predictable (more uncertain). The highest possible entropy for a position depends on the alphabet (set of items) that can appear there. Because the sets of possible items for consonants, vowels, and stress are different, they have different maximum entropies.
Let’s build a quick positional entropy heat-map with the ‘afterburner’ set we just generated.:
>>> matches = 'afterburner afterburners ernsberger ferderer herberger hershberger herzberger kirchberger murderer murderers murderers nurnberger nurturer paperworker paperworkers perjurer schermerhorn sternberger verderber'.split(' ')
>>> matches = '\n'.join(matches)
>>> matches_phonomials = phonesse.phonomial.from_string(matches,split='lines')
>>> phonesse.plot_phrase_set_summary(matches_phonomials,3,'right')
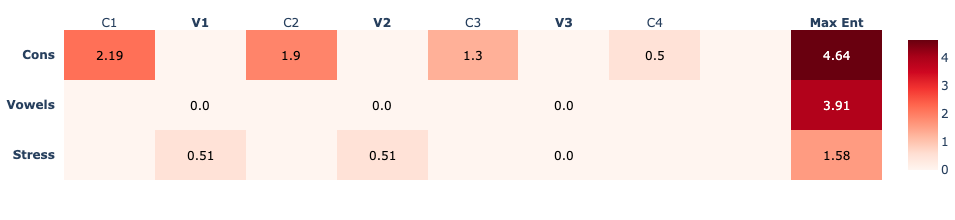
The plot_phrase_set_summary takes a list of phonomials (each a word or phrase), a number of columns to extract, and an alignment (right or left). It will extract n syllables (columns)from the right or left of each phonomial and plot a summary heat-map that compares the same position in each phonomial. Hovering over each position in the heat-map shows the frequency of sound segments in each position, the number (& color) in each box indicates its entropy.
Notice that because we created this list by holding all the vowels constant, the entropy for all 3 vowel positions is 0.0, meaning these positions are perfectly predictable. The deeper the red color, the more uncertain we are about which sound will occur in any given position. Here, we can see a left-to-right trend of increasing predictability (lower entropy) in consonant positions. This is common in the lexicon.
Here is a positional entropy heat-map of the words from a rhyming game:
>>> rhymes_phonomials = phonesse.phonomial.from_string(phonesse.data.get_sample('bar_pong_rhymes').strip(),split='lines')
>>> phonesse.plot_phrase_set_summary(rhymes_phonomials,4,'right')
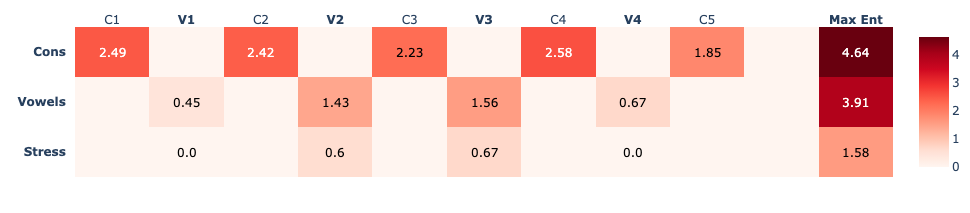
The highest entropy we can describe for a variable (position) is when it is uniformly distributed, i.e. every item is as likely as every other. For example, in order for a vowel position to reach maximum entropy, every vowel would have to occur in the position exactly the same number of times. If one particular vowel occurs more often than others, then that vowel is more likely, thus the position has become more predictable and the entropy value will drop. If only one item ever appears in a position, its entropy will be 0.0, perfectly predictable.
These kinds of heat-map plots can give us a quick sense of the shape of the underlying sound patterns in fixed sets of utterances.
Errors¶
Discrete representations of sound items in language are useful, but are problematic for a number of reasons beyond their simplification of the underlying continuous signals. In 2001, George Miller noted that the ambiguity of the dictionary meanings of words creates a combinatorial explosion which makes the human ability to interpret meaning in language quite remarkable. Individual words have many meanings, and even within Standard American English, orthographic representations leave us with too many possibilities to be certain of the ‘true’ or intended representation.
This combinatorial explosion is show below. Possible meanings are used to calculate how many distinct possible interpretations there are of a given sentence when using simple lookup dictionaries (Miller 2001). But this ambiguity also applies to the representation of pronunciation.

I have conservatively conducted the same exercise with all possible pronunciations of these same words from the CMU pronouncing dictionary of Standard American English to identify 72 possible and distinct pronunciations of this sentence. This highlights the need to acknowledge uncertainty in the faithfulness of discrete representations of sounds, even in simple or obvious-seeming utterances. The level of ambiguity in pronunciation is not as great as that of meaning, but it does still exist. This is not even taking into account differences in pronunciations of dialects or individual speakers.
Uncertainty here is an issue that is ever present, particularly when conducting analyses not based on (or grounded by) audio recordings of speakers. Many forms of analyses, the present toolkit included, fall victim to this problem, as they are based on orthographic representations alone. Despite this, a great deal of progress can still be made by studying sound patterns extracted from the orthographic representations of words.
Future Work¶
Phonesse is just getting started. I hope to make performance and feature improvements over time.
Some things that are coming in the future are listed below.
- Syllabic NN support
- Methods for attested phrases and corpus studies
- Distinctive feature support
- Example case studies
- Data sets
- Encoding phonomials from audio files